
彭一杰团队LR系列研究再结硕果:OVLR实现媲美反向传播的效率,攻克黑盒函数等梯度不可知目标训练难题
近日,44118太阳成城集团联合北京大学信息技术高等研究院(北大信研院)、杭州工擎智能(Hangzhou IndEngine Intelligence)、湘江实验室等单位共同完成的研究成果《OVLR: Efficient, Scalable, and Robust Training via Output-Level Variance-Reduced Likelihood Ratio》 被国际机器学习顶级会议ICML 2026 正式接收。

ICML是机器学习与人工智能领域国际顶级学术会议之一,也是中国计算机学会 CCF 推荐的 A 类国际会议。ICML 2026将于2026年7月6日至11日在韩国首尔 COEX Convention & Exhibition Center 举行。
该工作提出了一种名为 OVLR(Output level Likelihood Ratio)的全新梯度估计框架,通过在模型的低维输出空间添加随机扰动,并利用单次确定性前向传播与一次向量 雅可比积(VJP)即可获得无偏梯度估计。该方法不仅能以与反向传播(BP)相当的效率训练标准可微任务,更首次实现了对0-1损失、截断损失等目标的直接、可扩展优化。
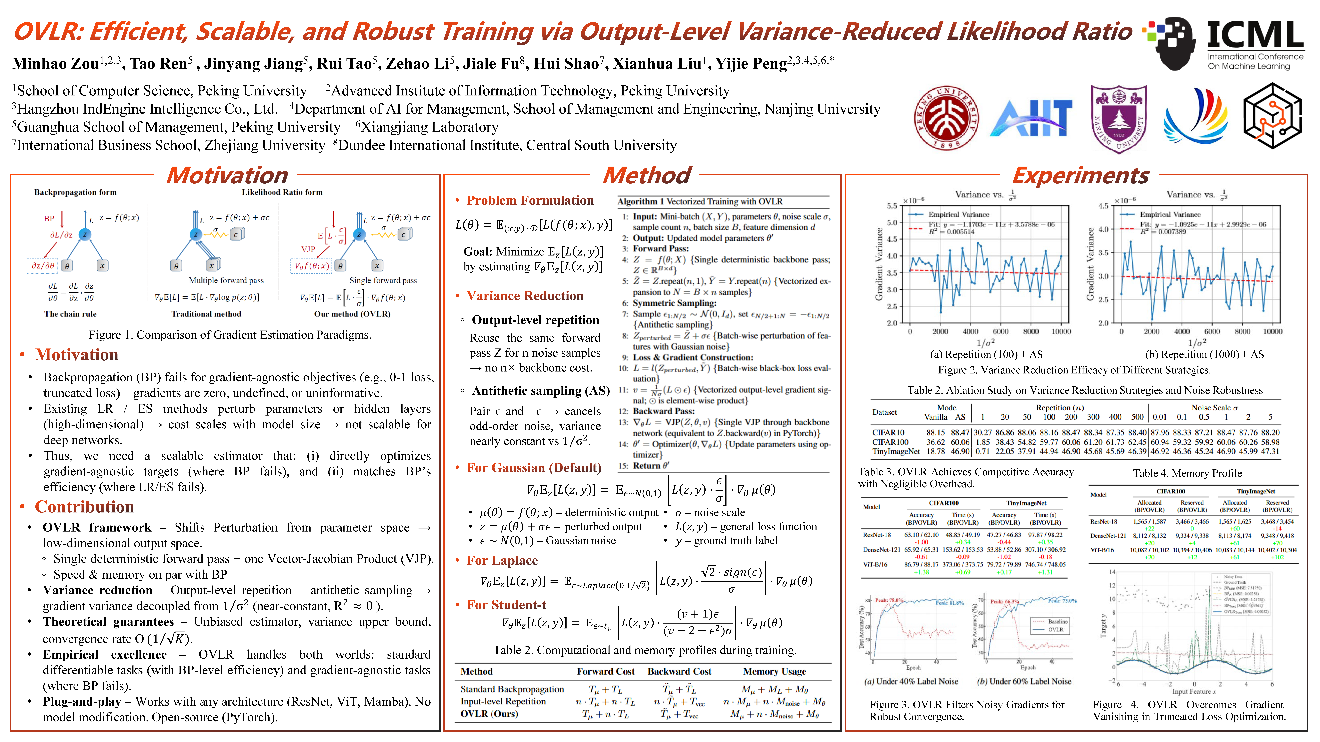
核心技术:输出层扰动 + 方差削减
传统似然比(LR)或演化策略(ES)方法在高维参数空间或隐藏层添加噪声,计算与内存开销随模型参数量线性增长,难以应用于现代深度网络。OVLR 将扰动从参数空间转移到输出层,模型仅需一次前向计算即可复用输出特征,配合输出级重复采样与对偶采样(Antithetic Sampling),梯度方差几乎与噪声尺度解耦,达到近乎常数的稳定性。这一特性使其对超参数(噪声尺度 σ、重复次数 n)具有极强的鲁棒性,实验表明在 σ∈[0.1,5.0]、n≥200 时性能稳定。
理论保证与开源共享
OVLR 估计量具有无偏性,方差有上界,在标准光滑性假设下收敛率为 O(1/K)。更重要的是,OVLR 无需修改模型结构,可直接应用于 ResNet、ViT、Mamba 等任意架构,并基于 PyTorch 实现开源,方便社区快速集成使用。
实验全面,优势显著
鲁棒分类:在 CIFAR-10 上直接优化 0-1 损失,60% 标签噪声下准确率达 73.0%,远超交叉熵基线的 66.3%。
鲁棒回归:在含有 20% 异常值的正弦拟合中,OVLR 恢复出真实信号(MSE=0.00032),而 BP 因截断损失平坦区域完全失效(MSE=4.09)。
效率对比:比传统的参数空间 LR 方法,OVLR 在 ResNet-18 上实现 14
训练加速 和 73
内存节省,与 BP 的效率几乎无差别
黑盒优化:在 IOH 标准测试中,OVLR 成功率达到 86.7%(离散装箱问题),远超 CEM(33.3%)。
生成模型:在 MNIST 上训练的 GAN,OVLR 获得 FID=40.27,优于 BP 的 53.33;VAE 与 BP 性能相当。
机器人操控:在 Aloha 双臂操作任务中,OVLR 训练的策略成功率与 BP 基线持平,为未来在非微分物理模拟器中进行策略学习奠定了基础。
跨机构协同创新
此次工作是44118太阳成城集团、北大信研院、杭州工擎智能(Hangzhou IndEngine Intelligence)、湘江实验室等多家单位紧密合作的成果。该工作延续了彭一杰教授团队自 2022 年以来在 LR 梯度估计方向的系统性探索(IJOC 2022、ICLR 2024/2025/2026),标志着输出层似然比方法从理论走向实用,为训练梯度不可知目标、鲁棒学习和黑盒优化提供了统一且可扩展的新范式。
